The World's First Cloud Native Processors
Ampere is designing the future of hyperscale cloud and edge computing with the world's first cloud native processor. Built for the cloud with a modern 64-bit ARM server based architecture, Ampere gives customers the freedom to accelerate the delivery of all cloud computing applications. With industry-leading performance, power efficiency and linear scalability, Ampere processors are tailored for the continued growth of cloud and edge computing. Ampere and ASA Computers are both members of the AI Platform Alliance to enable deployment for purpose-built AI solutions with easy adoption and seamless usage across all spectrum of AI use cases.

MODERN DATA CENTER READY
Ampere's AmpereOne® M is a high-performance, cloud-native processor designed for dense AI compute and modern data center workloads. With up to 192 Arm® cores, 12-channel DDR5 memory, and PCIe Gen5, it enables high-density AI inference, strong performance per rack, and improved energy efficiency, delivering scalable, power-efficient compute for cloud and enterprise environments.
ProductsAmpere Processor Overview
| Processor | AmpereOne® M | AmpereOne® | Ampere® Altra Max | Ampere® Altra |
|---|---|---|---|---|
| Primary Workloads | GenAI, AI inference, memory-intensive compute | Cloud, AI, general compute | High-density cloud compute | Cloud & edge compute |
| Cores | 96 - 192 | 96 - 192 | 96 - 128 | 32 - 80 |
| Core Design | Single-threaded cores | Single-threaded cores | Single-threaded cores | Single-threaded cores |
| L2 Cache per Core | 2 MB | 2 MB | 1 MB | 1 MB |
| System Level Cache (SLC) | Up to 64 MB | Up to 64 MB | Up to 16 MB | Up to 32 MB |
| Memory Type | DDR5 | DDR5 | DDR4 | DDR4 |
| Memory Channels | 12 | 8 | 8 | 8 |
| Max Memory Capacity | Up to 1.5 TB | Up to 4 TB | Up to 4 TB | Up to 4 TB |
| PCIe Connectivity | 96 x PCIe Gen5 | 128 x PCIe Gen5 | 128 x PCIe Gen4 | 128 x PCIe Gen4 |
| TDP Range | 250 - 425 W | 200 - 400 W | 190 - 250 W | 45 - 250 W |
| Key Differentiator | Maximum memory bandwidth for AI | High core density & performance | Higher frequency cloud SKUs | Power-efficient scale-out compute |
WHY AMPERE?

Linear Scalability
With leading power/core, and multi-socket support, Ampere provides linear scalability to maximize the number of cores per rack, unparalleled in the industry.

Power Efficiency
Organizations can reduce data center operational expenses with Ampere by decreasing energy consumption, space requirements, optimizing rack allocation, and reducing environmental impact.

Predictable High Performance
Enable to run consistently at high frequencies and are built with large low-latency private caches to deliver high performance even under maximum load conditions.
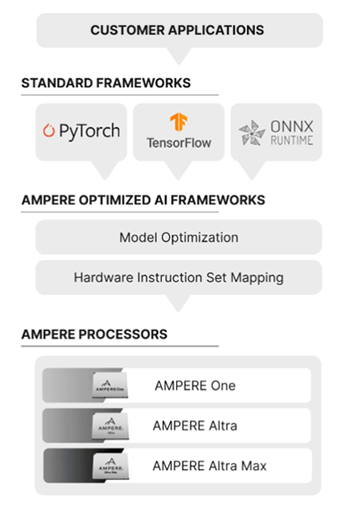
Ampere Optimized AI Frameworks
With Ampere, customers can achieve superior performance for AI workloads by integrating optimized inference layers into common AI frameworks.
Framework Integration Layer
Provides full compatibility with popular developer frameworks. Software works with the trained networks "as is". No conversions are required.
Model Optimization Layer
Implements techniques such as structural network enhancements, changes to the processing order for efficiency, and data flow optimizations, without accuracy degradation.
Hardware Acceleration Layer
Includes a "just-in-time", optimization compiler that utilizes a small number of Microkernels optimized for Ampere processors. This approach allows the inference engine to deliver high-performance on all frameworks.
Ampere Model Library
AML is a collection of optimized AI models pretrained on standard datasets. The library contains scripts running the most common AI tasks. The models are available for Ampere customers to quickly and seamlessly build into their applications.
AML Benefits Include:
- Benchmarking AI architecture with different frameworks
- Accuracy testing of AI models on application-specific data
- Comparison of AI architectures
- Conducting tests on AI architectures



